Introduction



Data management framework for Python that provides functionality to describe, extract, validate, and transform tabular data (DEVT Framework). It supports a great deal of data schemes and formats, and provides popular platforms integrations. The framework is powered by the lightweight yet comprehensive Frictionless Data Specifications.
Why Frictionless Data?#
Generating insight and conclusions from data is often not a straightforward process. Data can be poorly structured, hard to find, archived in difficult to use formats, or incomplete. These issues create “friction” and make it difficult to use, publish and share data. The Frictionless Data project aims to reduce frictions while working with data, with a goal to make it effortless to transport data among different tools and platforms for further analysis. This project is a suite of open source software, tools, and specifications focused on improving data and metadata interoperability. The core software library is Frictionless-py, and this documentation will help you learn how to use this Frictionless Framework. Are you interested in learning more about the project as a whole? Read the overview section below.
Frictionless Standards#
The core of the Framework are the Frictionless Standards. These standards are a set of patterns for describing data including Data Package (for datasets), Data Resource (for files) and Table Schema (for tables). A Data Package is a simple container format used to describe and package a collection of data and metadata, including schemas. Frictionless-py lets users create data packages and schemas that conform to the Frictionless specifications. You can read more about the Frictionless standards at https://specs.frictionlessdata.io/. The main concepts of the Frictionless Standards are:
Table Schema: a metadata file usually written in JSON or YAML that describes a tabular file by providing its dimension, field data types, relations, and constraints. One Table Schema can be used with many tabular files with the same structure.
Data Resource: a metadata file usually written in JSON or YAML that describes an EXACT tabular file providing a path to the file and details like title, description, and others. For a tabular resource it also includes a Table Schema from above.
Data Package: a metadata file usually written in JSON or YAML that describes a COLLECTION of EXACT tabular files providing data resource information from above along with general information about the package itself as though a license, authors, and other metadata.
tip
Thinking in SQL terminology a package would be a database, a resource would be a table, and a schema would be column definitions.
Frictionless Framework#
The Frictionless Framework makes data more usable by generating metadata and schemas and by validating data to ensure quality. There are four main functions that can be used independently to improve your data: Describe data, Extract data, Validate data, and Transform data (DEVT). Here, we will go into more detail on each of these main functions.
Describe your data: infer and edit metadata from a data file. For instance, describe will generate metadata describing the layout of the data (i.e. which row is the header) as well as a schema describing the data contents (i.e. the type of data in a column). This is a first step for ensuring data quality and usability.
Extract your data: read and normalize data from a data file. By default, extract returns data conforming to the metadata that was either defined in the describe step or inferred automatically. The user can opt-out of this to get the raw (unnormalized) data. Frictionless supports various file schemes like HTTP, FTP, and S3 and data formats like CSV, XLS, JSON, SQL, and others.
Validate your data: detect errors in a data file. validate runs checks on data tables, resources, and datasets to identify potential issues (i.e. are there any missing values?). These checks can be modified and can be based on a provided schema. While extract cleans the data by removing the invalid cells, validate helps to see the whole picture of the raw file.
Transform your data: change a data file's metadata and data. This step can including reshaping data, saving it in a different format, or uploading the data somewhere. Frictionless provides a pipeline capability and a lower-level interface to work with the data.
Important Features#
Frictionless is a complete data solution providing rich functionality. It's hard to list all the features it provides, but here are the most important ones:
- Open Source (MIT)
- Powerful Python framework
- Convenient command-line interface
- Low memory consumption for data of any size
- Reasonable performance on big data
- Support for compressed files
- Custom checks and formats
- Fully pluggable architecture
- An included API server
- More than 1000+ tests
Usage Example#
Frictionless can be run on CLI, in Python, and even as an API server. Here is a short example how to validate a data file in CLI:
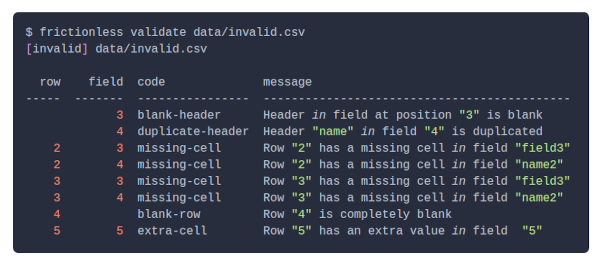
User Stories#
Frictionless is a DEVT-framework (describe-extract-validate-transform). In contrast to ETL-frameworks (extract-transform-load), Frictionless does not have a linear flow. For example, let’s look at some user stories:

Continue reading this documentation to learn more about it!